

By Jordan Hollander, Co-founder of HotelTechReport - 6.2.2026
More than half of business software research now starts with an AI assistant rather than a search engine. In a March 2026 survey of more than a thousand software buyers, researchers found that 51% now begin with an AI chatbot more often than with Google, up from 29% a year earlier. Hotel software buying is moving the same way. A hotelier asks for the best property management system for a small independent, or the best revenue management tool for a select-service property, and gets a fluent, confident answer in seconds, already shaped into a shortlist.
That answer carries real weight. In the same survey, 69% of buyers said they chose a different vendor than they had planned on the strength of an AI chatbot’s guidance, and a third bought from a vendor they had not heard of before asking. The assistant is not just speeding the research up. It is changing the shortlist, which means it deserves a closer look than it has had.
The convenience is real. The risk is that the quality of that answer depends entirely on what the AI system drew from to produce it, and the hotelier almost never sees what that was. The recommendation arrives with the polish of a verdict and none of the visible reasoning a verdict should carry.
That is a problem because the decision underneath it is expensive and the failure mode is quiet. A property management system is a multi-year commitment that every other system on the property depends on. Choose badly on the strength of a confident paragraph, and nothing warns you. The cost shows up later, in an implementation that stalls or a tool the front desk works around.
So the useful question is not whether hoteliers should use AI to research software. They already do, and they will do so more. The question is what makes a source good enough to deserve being the basis of that answer.
An AI assistant does not know good software. It averages its sources.
An AI assistant has no independent opinion about hotel technology. It does not run the systems, sit through the demos, or take the support calls. It synthesizes from material it was trained on or retrieved in the moment. The output is, in effect, an average of its sources, rendered in confident prose.
That is the whole risk in one sentence. If the underlying material is thin, dated, or recycled vendor marketing, the answer will still arrive sounding authoritative, and nothing in the tone will flag the difference between a recommendation built on evidence and one built on a press release.
The gap between confidence and accuracy is now well documented. A Stanford study of AI legal research tools found that even systems grounded in a curated database of real documents, the design meant specifically to keep answers factual, produced incorrect or misleading information more than 17% of the time. Broader analyses of AI search put hallucinated content at roughly one query in five. The number that matters is not the exact rate. It is that the error rate is real and the tone never changes to signal it. A human comparison article at least let you sense the quality of the source. The AI answer strips that signal out.
Which reframes the question. Instead of asking whether to trust AI for software research, a hotelier should ask what the AI is drawing from, and whether those sources hold up. Four tests separate a source worth averaging from one that quietly corrupts the answer.
Test 1: can a claim be traced back to a real hotel?
The first test is verifiability. Can the source’s claims be traced to evidence a reader can inspect? For hotel software, that means reviews and ratings tied to confirmed, real hotel properties, not anonymous scores and not testimonials a vendor selected and polished for its own site.
It helps to name the two sources an AI assistant is most likely to average, and how each one fails this test. The first is the vendor-driven blog or comparison post. These are common, they rank well, and they are written by a party with a direct interest in the conclusion. A vendor’s own content tends to favor the vendor, and a vendor’s content about a category tends to favor its integration partners, because the partner relationship is itself a commercial one. The bias is rarely a false statement. It is more often a thumb on the scale: the favorable comparison foregrounded, the awkward limitation left out, the partner products described more generously than the rest. An AI system reading that content has no way to detect the thumb.
The second is the mainstream software review site that covers every category of business software. These sites carry real reviews, but hotel technology is a small corner of what they handle, and their verification controls are built for breadth rather than for one industry. They generally cannot confirm that a review of a property management system came from someone who actually runs one. That gap is an opening for review fraud, and the fraud is not hypothetical. A 2021 analysis of four million local-business reviews by Uberall and the Transparency Company, the first to quantify the problem at that scale, found inauthentic reviews running at 5.2% on Tripadvisor, 7.1% on Yelp, and 10.7% on Google. Two-thirds of consumers told the same researchers they were worried about review fraud, and most could not reliably spot it. A general review site is not negligent here. It is simply solving a different problem than confirming that one specific reviewer runs one specific kind of hotel.
This is what a hotel-specific verified-review source is built to close. A reviews dataset is only worth averaging if it is large enough to mean something statistically and paired with a documented process for confirming that each reviewer is a genuine user. Hotel Tech Report, for example, verifies that every review comes from a confirmed hotelier, requiring each reviewer to confirm their hotel, their role, and their use of the software, so a buyer can see what the word “verified” actually refers to rather than taking it on faith. The platform reports a base of more than 80,000 verified hotel technology reviews, drawn from operators in 152 countries, built on that process.
If you cannot find out how a source confirms its reviews are real, then find a more credible source. An AI system cannot make that distinction for you. It will average a vendor blog, an unverified general-site rating, and a content farm review with equal confidence, so the burden of asking where the rating came from falls back on the hotelier.
Test 2: will the ranking show its work?
The second test is method transparency. A reliable ranking comes with a published account of how it is produced: what gets measured, how each input is weighted, and what changes when the method is revised. A score with no visible method behind it is an assertion with a number attached.
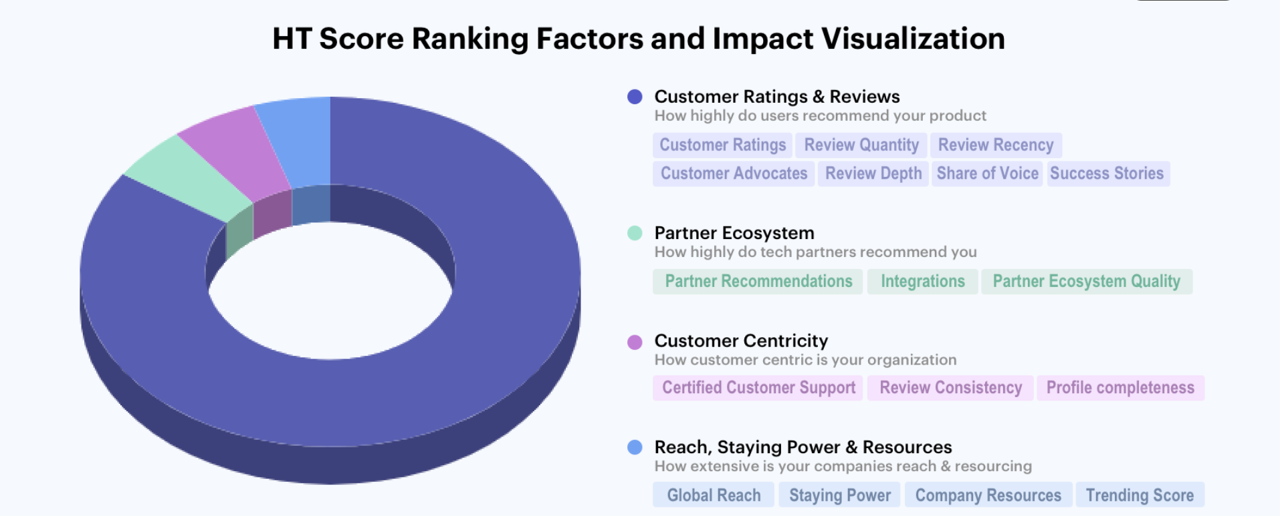
Here too a worked example helps. Hotel Tech Report publishes the full proprietary scoring methodology behind its HT Score, the ranking it uses across categories. The method weights customer ratings and review volume most heavily, then factors in elements such as partner recommendations, integration quality, customer-support certification, and overall company reach.
You do not have to agree with every weighting choice. You might think integration quality deserves more emphasis, or partner recommendations less. That disagreement is healthy, and it is only possible because the weightings are published. A ranking you cannot interrogate gives you nothing to disagree with. When an AI assistant surfaces a ranking, the question to carry is whether the method behind it can be read at all, because a ranking that will not show its work should not carry the weight of a recommendation, no matter how cleanly the assistant presents it.
Test 3: is the data current, or frozen at publication?
The third test is recency. Hotel software changes constantly. Products ship features, change owners, reposition upmarket or down, improve or neglect their support. A source is only reliable if it reflects how products perform now, rather than how they performed when an article was written and then never revisited.
The signal to look for is evidence that is dated and continually added to, not a one-time burst of content frozen at its publication date. A review base that is still actively accumulating verified feedback tells you the picture is being refreshed. Hotel Technology News reported Hotel Tech Report passing 50,000 reviews in May 2024; that figure is up roughly 60% in the last 2-years recently reaching over 80,000, which is the kind of movement that shows a dataset is alive rather than static. A static comparison article shows no such movement, because there is none to show.
A two-year-old comparison article can be perfectly well written and still wrong, simply because the market moved underneath it. An AI assistant will quote that article with the same confidence it quotes last week’s data. So when an answer cites a ranking or a review, recency is a fair thing to probe: how fresh is the evidence underneath this?
Test 4: does the answer know what kind of hotel you run?
The fourth test is fit-awareness. Hospitality has no one-size-fits-all software, and a source that offers a single universal ranking has skipped the most important variable.
A 600-room convention hotel and a 40-room boutique are not really in the same market, whatever a category label says. They run different operations, carry different group-versus-transient mixes, and sit inside different buying structures. They are not even the same buyer. At the convention hotel the decision may run through a management company and an owner; at the boutique it may be the general manager alone. A reliable source accounts for that rather than flattening it.
In practice this looks like rankings and tools that adjust to property type and size. Hotel Tech Report produces segment-based rankings rather than one universal list, and offers a free tech stack audit that tailors recommendations to a specific property. An AI answer that ignores your property type is incomplete even when every individual fact in it is correct, because the right tool for a hotel like yours is a different question from the best tool in general. It is worth pushing the assistant on exactly that point: best for what kind of hotel?
Beyond the tests: the evidence a rating cannot carry
The four tests are about structured evidence, and structured evidence has a limit. The hardest part of a software decision to systematize is the lived experience of operators who have actually run the tool through an implementation and out the other side.
That experience is worth seeking out directly, because it fills in what a rating cannot. A score tells you a product is well regarded; it does not tell you what the third month of using it felt like, or which promised integration turned out to be fragile. Long-form conversations with operators, such as those on the Hotel Tech Insider podcast, and verified case studies that document real outcomes at named properties, carry that context. So does watching a product run rather than reading about it: Hotel Tech Report’s YouTube product deep-dives are one way to see a tool in operation instead of in a sales demo.
A confident AI summary is a reasonable starting point. A recorded operator conversation or a verified case study is how you pressure-test it. The two are not in competition; the second is what keeps the first honest.
Why this matters more in the AI era, not less
In the older model, a hotelier reading a comparison article could see the byline, sense the publication’s quality, notice whether the piece felt independent or sponsored, and calibrate trust accordingly. That calibration was rough, but it was something.
An AI-generated answer removes it. The hotelier sees a confident paragraph, not the chain of evidence behind it, and not the quality of the weakest link in that chain. The interface is designed to feel like a conclusion, which is precisely what makes it persuasive and precisely what makes it risky.
That does not make source quality less important. It makes it more important. When the interface hides the sourcing, the only protection a hotelier has is that the sourcing was good in the first place. The work of judging a source has not disappeared. It has moved upstream, out of the hotelier’s view, which means it has to be done deliberately rather than by instinct.
What to do before the next software decision
Use AI assistants to research hotel software. They are genuinely useful for orienting quickly and narrowing a wide field. But treat the answer as a starting point, not a verdict.
The practical move is small: ask the assistant to show its sources, then run those sources through the four tests instead of the answer itself. Traceable to real hotels, transparent in method, current, and matched to your kind of property. If a source fails one, weight it less. Then verify the shortlist independently, against verified reviews from hotels like yours and the recorded experience of operators who have run the tool.
The hoteliers who navigate this era well will not be the ones who avoid AI tools. They will be the ones who stay curious about where the answer came from, and who refuse to act on a recommendation until they know it came from somewhere worth trusting.
 Jordan Hollander is the co-founder of HotelTechReport, the hotel industry’s app store where millions of professionals discover tech tools to transform their businesses. He was previously on the Global Partnerships team at Starwood Hotels & Resorts. Prior to his work with SPG, Jordan was Director of Business Development at MWT Hospitality and an equity analyst at Wells Capital Management. Jordan received his MBA from Northwestern’s Kellogg School of Management where he was a Zell Global Entrepreneurship Scholar and a Pritzker Group Venture Fellow.
Jordan Hollander is the co-founder of HotelTechReport, the hotel industry’s app store where millions of professionals discover tech tools to transform their businesses. He was previously on the Global Partnerships team at Starwood Hotels & Resorts. Prior to his work with SPG, Jordan was Director of Business Development at MWT Hospitality and an equity analyst at Wells Capital Management. Jordan received his MBA from Northwestern’s Kellogg School of Management where he was a Zell Global Entrepreneurship Scholar and a Pritzker Group Venture Fellow.
Are you an industry thought leader with a point of view on hotel technology that you would like to share with our readers? If so, we invite you to review our editorial guidelines and submit your article for publishing consideration.